Metodologia badań
Obszar badań
Nagrania prowadzone są obecnie na terenie całego szeroko rozumianego dialektu mazowieckiego obejmującego 10 regionów, czyli Mazowsze bliższe, Mazowsze dalsze, Kurpie, Mazury, Warmię, Ostródzkie, Lubawskie, Podlasie, Suwalszczyznę i Łowickie. W projekcie częściowo wykorzystywane są nagrane wcześniej na terenie Mazowsza teksty przechowywane w Instytucie Języka Polskiego Uniwersytetu Warszawskiego.
Informatorzy
W badaniach uczestniczą kobiety i mężczyźni w wieku od 20 lat wzwyż, pochodzący ze wsi danego regionu co najmniej w drugim pokoleniu. Uwzględnienie w bazie także osób młodszych ukazuje zależne od wieku respondentów zróżnicowanie fonetyczne gwar mazowieckich oraz pozwala na nakreślenie tendencji wymawianiowych istniejących w badanych gwarach w obrębie samogłosek. Wybrani informatorzy nie posiadają wad wymowy oraz ubytków słuchu.
Zestaw metadanych uwzględnionych w opisie informatora przedstawia się następująco – wieś i jej współrzędne geograficzne, region, gmina, powiat, województwo, płeć i wiek informatora, miejsce urodzenia informatora, miejsce urodzenia rodziców informatora, miejsce urodzenia dziadków informatora, wykształcenie informatora, wykształcenie rodziców informatora, wykształcenie dziadków informatora. Liczebność próby to minimum 6 osób z jednego regionu.
Do badań porównawczych wykorzystano próbki dźwiękowe polszczyzny ogólnej, pochodzące od 6 osób (3 kobiety, 3 mężczyzn), z wykształceniem wyższym, głównie polonistycznym, reprezentujących trzy grupy wiekowe (20-40, 40-60, 60-80 lat). Wszystkie osoby pochodziły z miast Mazowsza od trzeciego pokolenia wstecz.
Stopniowo baza będzie uzupełniana o nagrania kolejnych osób reprezentujących zarówno polszczyznę gwarową, jak i ogólną.
Materiał badawczy
Akustyczna baza danych gwar mazowieckich została zaprojektowana tak, aby zawierała dużą liczbę nagrań zarówno kobiet, jak i mężczyzn, reprezentujących zróżnicowanie dialektalne obszaru Mazowsza, i była dostępna dla analiz akustycznych. Od każdego mówcy uzyskano około godziny spontanicznej wypowiedzi na różne tematy. W przypadku osób reprezentujących zróżnicowanie gwarowe zrezygnowano z form czytanych, ponieważ każda tego typu próba powodowała przechodzenie na polszczyznę ogólną. Odpowiednio przygotowane pod względem fonetycznym, tak, aby zawierały wszystkie uwzględnione w projekcie konteksty, teksty czytane (wyrazy, zdania, opowiadanie) oraz spontaniczne uzyskano natomiast od osób reprezentujących polszczyznę ogólną, stanowiącą w projekcie materiał porównawczy. Ponieważ we wstępnych badaniach w zakresie wartości F1, F2 nie uzyskano istotnych statystycznie różnic między samogłoskami w tekstach czytanych i spontanicznych, wszystkie te dane wykorzystano razem w celach porównawczych. Z uzyskanych tekstów spontanicznych wyekscerpowano samogłoski ustne akcentowane i nieakcentowane w następujących kontekstach spółgłoskowych:
- obustronny twardy niesonorny, np. baba;
- lewostronny miękki, np. ciotka;
- prawostronny miękki, np. kociak;
- obustronny miękki, np. ciocia;
- lewostronny sonorny nienosowy, np. las;
- prawostronny sonorny nienosowy, np. sala;
- obustronny sonorny nienosowy, np. lala;
- lewostronny sonorny nosowy, np. mak;
- prawostronny sonorny nosowy, np. kamyk;
- obustronny sonorny nosowy, np. mama;
- lewostronny ł, np. łuk;
- prawostronny ł, np. kuł;
- samogłoski w wygłosie tylko po spółgłoskach twardych.
Konteksty zostały zanalizowane osobno, ponieważ wpływ kontekstu poprzedzającego jest silniejszy niż następującego. Istnieją także różnice między jednostronnym a obustronnym wpływem danego kontekstu. Wyekscerpowane samogłoski są charakteryzowane pod względem formantu pierwszego i drugiego oraz automatycznie nanoszone na wykres o współrzędnych F1 i F2.
Nagrania
Nagrania przeprowadzono przy użyciu dyktafonu cyfrowego Olympus DM-650 oraz mikrofonu SONY ECM – MS907, w formacie Linear PCM przy częstotliwości próbkowania 44 kHz, w domach informatorów. Jeśli chodzi o warunki nagrań najlepsze są warunki studyjne, które jednak pociągają za sobą koszty i sprzyjają wymowie laboratoryjnej, tak zwanej lab speech (Labov i in. 1972; Rischel 1992). Z drugiej strony badania w terenie dają bardziej naturalną wymowę, ale nagrania są zawsze gorszej jakości i zawierają więcej szumów i dźwięków otoczenia (Plichta, Mendoza-Denton 2001). Zdecydowano się na nagrania w domach informatorów ze względu na różne czynniki, przede wszystkim koszty związane z wykorzystaniem profesjonalnego studia, naturalność wymowy, wiek informatorów, niechęć i obawy informatorów związane z wyjazdem do studia. Podczas sesji nagraniowej starano się zachować warunku zbliżone do studyjnych, np. proszono o wyłączenie telewizora, lodówki, pralki itp., o zamknięcie okien. Nagrania przeprowadzano w cichym pokoju tylko z jedną osobą. Osoby reprezentujące wymowę ogólnopolską nagrywano również w warunkach niestudyjnych (biblioteka), aby uzyskać warunki zbliżone do nagrań terenowych. Sesja nagraniowa trwała około godziny.
Segmentacja i transkrypcja
Segmentacja sygnału mowy została przeprowadzona według zasad zawartych w opracowaniu (Machač, Skarnitzl 2009). Brano pod uwagę spektrogramy oraz obecność pełnej struktury formantowej w obrębie samogłoski i jej brak lub zmiany przy spółgłosce, por. rys. 1.
Rys. 1. Samogłoska y w wyrazie krzyża (przebieg formantów oznaczono czerwonymi kropkami).
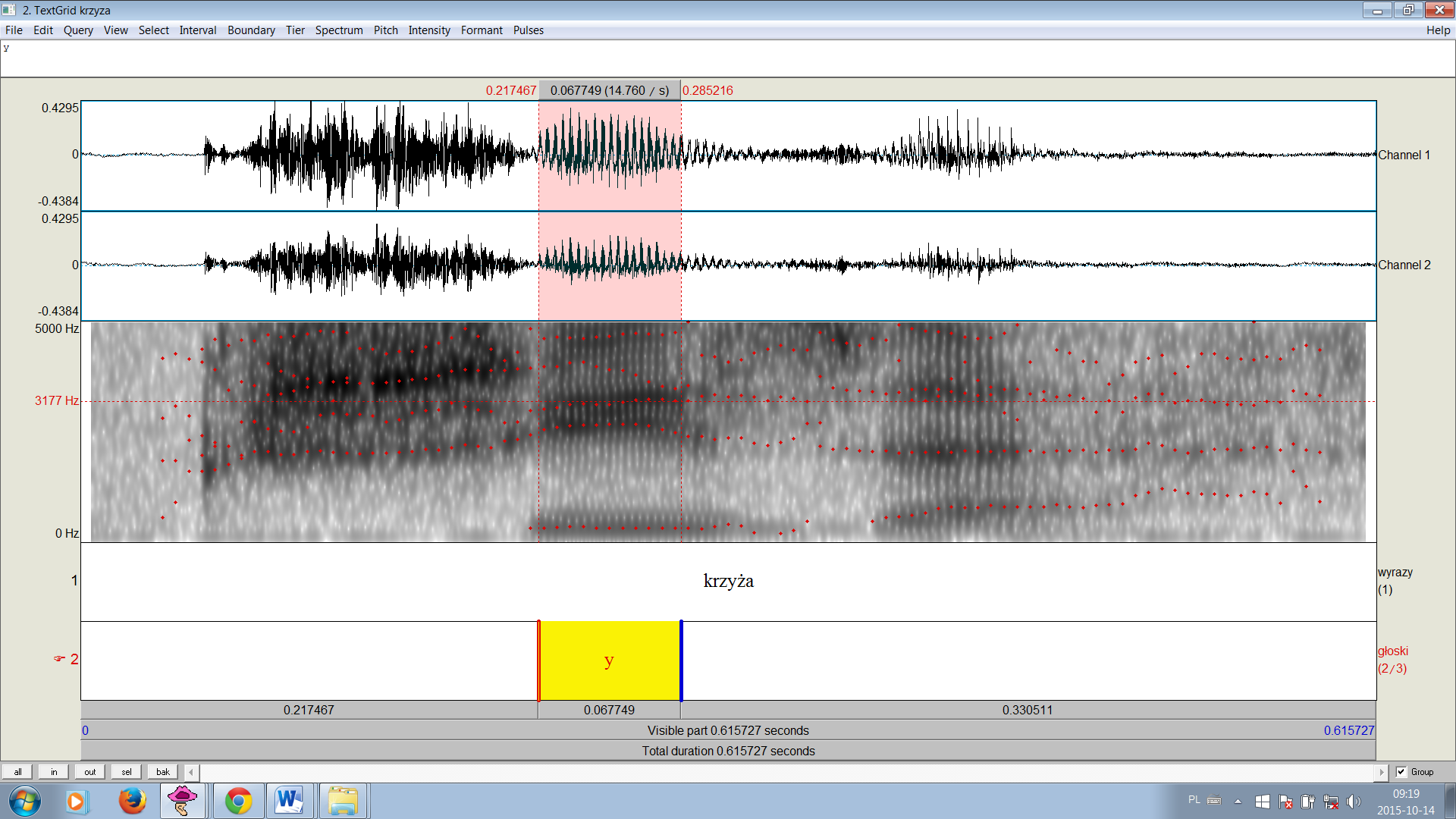
W bazie zastosowano transkrypcję ręczną. Baza danych nie jest korpusem tekstów mazowieckich odzwierciedlających wszystkie cechy gwarowe danego regionu. Ponieważ celem projektu jest analiza akustyczna samogłosek, nie przewiduje się pełnego zapisu fonetycznego tekstów, który jest już w pewnym stopniu interpretacją materiału dźwiękowego, lecz zapis powszechnie stosowanym w bazach akustycznych alfabetem SAMPA, który nie odzwierciedla np. stopnia ścieśnienia samogłosek. Tego typu zjawiska samogłoskowe użytkownik bazy będzie mógł sam zinterpretować na podstawie oglądu załączonych wykresów. Niemniej jednak w bazie uwzględniono najważniejsze charakterystyczne dla dialektu mazowieckiego cechy wymowy spółgłosek, takie jak mazurzenie, np. capka ‘czapka’, sziakanie, np. cziapka ‘czapka’, dźwięczna wymowa h lub asynchroniczna realizacja spółgłosek wargowych miękkich, np. bziały ‘biały’.
Pomiar formantów
Przy pomiarze wartości docelowych formantów brano pod uwagę środkową część samogłoski po odcięciu 20% początkowego i końcowego fragmentu jej trwania, aby zminimalizować wpływ sąsiedniego kontekstu. Ponieważ w wielu wypadkach nie udało się wydzielić ustalonej części samogłoski, wartość docelową pobierano zawsze:
- dla samogłosek przednich w punkcie, w którym F2 osiągało najwyższą wartość (Watson, Harrington 1999);
- dla samogłosek tylnych w punkcie, w którym F2 osiągało najniższą wartość;
- dla samogłoski [a] w punkcie, w którym F1 osiągało najwyższą wartość.