Struktura akustyczna samogłosek TODO
Powietrze wypełniające kanał głosowy jest w czasie realizacji samogłosek pobudzane do drgań przez drgające periodycznie lub quasi-periodycznie fałdy głosowe, zamykające i otwierające głośnię. Drgające powietrze reaguje rezonansem na drgania o tych częstotliwościach, które odpowiadają częstotliwościom rezonansowym kanału głosowego (Wierzchowska 1967). Częstotliwości rezonansowe są określane przez rozmiar i kształt jam nasady, właściwy dla poszczególnych samogłosek. W takim ujęciu rezonans można opisać jako akustyczną odpowiedź cząsteczek powietrza w jamie ustnej, nosowej i gardłowej na pewne źródło dźwięku, które wprawia je w drgania.
Źródło krtaniowe
Powietrze wypływające z płuc pod pewnym ciśnieniem napotyka na swej drodze zaporę w postaci zsuniętych fałdów głosowych. Ciśnienie, które jest wytwarzane za zamkniętą głośnią powoduje rozwarcie fałdów. Gdy nacisk powietrza na fałdy ustaje, zsuwają się one ponownie i ponownie gromadzi się pod nimi wypływające z płuc powietrze, którego ciśnienie znów powoduje ich rozsunięcie (Wierzchowska 1965).
Efektem działania fałdów głosowych jest ton krtaniowy, będący drganiem złożonym regularnym, którego spektrum zawiera harmoniczne, stanowiące wielokrotności częstotliwości podstawowej. Częstotliwości takie, ułożone w kolejności od najniższej do najwyższej, tworzą szereg harmoniczny. Największy wspólny podzielnik częstotliwości składowych harmonicznych odpowiada wartości częstotliwości podstawowej (F0), czyli częstotliwości drgania złożonego (Dukiewicz 1995). Fałdy głosowe mężczyzn są grubsze i dłuższe niż kobiet, co sprawia, że wibrują wolniej (F0 = 100-120 Hz), kobiece fałdy głosowe są krótsze i cieńsze, zatem wibrują dwukrotnie częściej (F0 = 200-250 Hz), por. (Simpson 2009). Przy normalnej fonacji ton krtaniowy charakteryzuje spektrum, które opada o około 12dB na oktawę (Fant 1960).
Rezonans akustyczny
Podczas wymawiania samogłoski neutralnej kształt jamy ustnej przypomina rurę o niezmiennym przekroju, która jest zamknięta na jednym końcu (fałdy głosowe w momencie zwarcia) i otwarta na drugim (usta) (Chiba, Kajiyama 1941). Rura tego typu stanowi rezonator o określonych właściwościach rezonacyjnych. Rezonans zajdzie w niej wówczas, gdy prędkość cząsteczek powietrza osiągnie maksimum przy jej otwartym końcu lub, w odniesieniu do kanału głosowego, przy ustach, zaś na zamkniętym końcu rury (odpowiednik zamkniętej przez fałdy głosowe głośni) prędkość cząsteczek będzie minimalna, ale ciśnienie będzie wysokie. Opisane tutaj drganie zachodzi, gdy długość rury jest równa ¼ długości fali (Chiba, Kajiyama 1941; Jassem 1973).
Częstotliwości rezonansowe rury otwartej na jednym końcu można obliczyć używając wzoru:
`R_n = ((2n - 1)c)/(4l)`
R - kolejne częstotliwości rezonansowe;
l – długość tuby w centymetrach;
n - kolejne liczby naturalne (tj. całkowite, dodatnie);
c – prędkość propagacji w centymetrach na sekundę (Fant 1960).
Dla typowego kanału głosowego mężczyzny o długości 17,6 cm (Fant 1960) i prędkości dźwięku w powietrzu wynoszącej 35200 cm/s, pierwszy rezonans będzie zatem wynosił:
`R_1 = ((2 - 1)*35200)/(4*17,6)= 500 Hz`
Z wzoru wynika, że kolejne rezonanse rury otwartej na jednym końcu będą stanowić nieparzyste wielokrotności najniższego rezonansu (Chiba, Kajiyama 1941; Jassem 1973; Raphael i in. 2007).
Druga częstotliwość rezonansowa będzie zatem trzykrotnie większa od najniższej (500Hz), ponieważ kiedy ¾ fali znajdzie się w rurze prędkość cząsteczek powietrza znowu osiągnie maksimum przy ustach. Dla drugiego rezonansu występują dwa punkty prędkości maksymalnej i dwa punkty maksymalnego ciśnienia w obrębie jamy ustnej.
Trzecia częstotliwość rezonansowa będzie częstotliwością, przy której 5/4 fali będzie mieściło się w długości tuby. Prędkość osiągnie maksimum w trzech miejscach, m.in. znowu przy ustach, i w trzech miejscach wystąpi maksimum ciśnienia.
Punkty maksymalnej prędkości i maksymalnego ciśnienia są ważne ponieważ częstotliwości rezonansowe zmieniają się, kiedy jama ustna przewęża się w pobliżu maksimum prędkości lub maksimum ciśnienia. Punkty maksymalnego ciśnienia odpowiadają punktom minimalnej prędkości i na odwrót. Przewężenie w punktach maksymalnej prędkości obniża częstotliwości rezonansowe, a przewężenie w punkcie maksymalnego ciśnienia podnosi częstotliwości rezonansowe (Raphael i in. 2007). Zatem różne konfiguracje kanału głosowego, odpowiadające poszczególnym samogłoskom, będą miały różne częstotliwości rezonansowe.
Kanał głosowy jest podobny do rezonatora opisanego wyżej z pewnymi zastrzeżeniami. W przeciwieństwie do sztywnej rury, kanał głosowy ma miękkie, absorbujące ściany i nigdy nie zachowuje stałego przekroju poprzecznego. Co więcej w kanale głosowym znajduje się zakręt pod kątem 90º, gdzie jama ustna spotyka się z jamą gardłową. Niemniej jednak porównanie kanału głosowego do rury otwartej na jednym końcu jest w zupełności wystarczające dla teorii produkcji mowy (Stevens, House 1955).
Filtracyjne właściwości kanału głosowego
Kształt i rozmiar ludzkich rezonatorów może się zmieniać poprzez ruch i pozycję narządów artykulacyjnych. Na przykład uniesienie masy języka zwiększa rozmiar jamy gardłowej, podczas gdy przesunięcie języka ku przodowi zmniejsza przestrzeń jamy ustnej. I odwrotnie, obniżenie masy języka redukuje przestrzeń jamy gardłowej, a cofnięcie masy języka zwiększa obszar jamy ustnej. Wysunięcie warg wydłuża zarówno jamę ustną, jak i cały kanał głosowy. Jak była mowa wyżej, gdy jama ustna tworzy kanał przypominający rurę o niezmiennym przekroju, wzmocnienia występują w pasmach o częstotliwościach centralnych 500 Hz, 1500 Hz, 2500 Hz i 3500 Hz. Gdy kanał ten zostanie w przedniej części zwężony, częstotliwości pierwszego i drugiego rezonansu znacznie się różnią, ponieważ częstotliwość pierwszego obniża się, zaś drugiego wyraźnie się uwydatnia. Gdy przewężenie jest blisko głośni, w tylnej części jamy ustnej, wartości dwóch pierwszych rezonansów są blisko siebie i w niskim zakresie częstotliwości. Długość kanału głosowego różni się również w zależności od wieku i płci danej osoby, co także ma wpływ na jego częstotliwości rezonansowe. Dłuższy kanał głosowy rezonuje przy niższych częstotliwościach niż krótszy, zatem częstotliwości rezonacyjne dla kobiet są wyższe niż dla mężczyzn, a u dzieci wyższe niż u dorosłych (Chiba, Kajiyama 1941; Jassem 1973; Wierzchowska 1965).
Drgania składowe tonu krtaniowego przenoszone są przez kanał głosowy w sposób wybiórczy: te spośród nich, których częstotliwość jest równa lub bliska częstotliwości drgań własnych rezonatora, tworzonego przez określony dla danej samogłoski układ narządów artykulacyjnych, ulegają wzmocnieniu, inne są w miarę zwiększania się różnicy między ich częstotliwością a częstotliwością rezonatora coraz bardziej tłumione (Dukiewicz 1995; Wierzchowska 1965). Na tym polega filtracyjna rola kanału głosowego, por. rys. 1.
Zatem kiedy ton krtaniowy przechodzi przez kanał głosowy, spektrum dźwięku wyjściowego jest wypadkową charakterystyki zarówno filtra, jak i źródła. Harmoniczne widoczne w spektrum samogłoski stanowią rezultat źródła krtaniowego, ale ich amplitudy to rezultat współdziałania źródła i funkcji przenoszenia kanału głosowego.
Rys. 1. Sposób wytwarzania niektórych samogłosek (za Moore 1999). Część (a) przedstawia widmo tonu krtaniowego. Część (b) przedstawia przekroje poprzeczne kanału głosowego w konfiguracjach odpowiadających trzem samogłoskom. Część (c) przedstawia charakterystyki przeniesienia kanału głosowego odpowiadające różnym jego konfiguracjom, właściwym poszczególnym samogłoskom. Część (d) przedstawia widma samogłosek po przejściu tonu krtaniowego (a) przez filtry o charakterystykach przedstawionych w części (c).
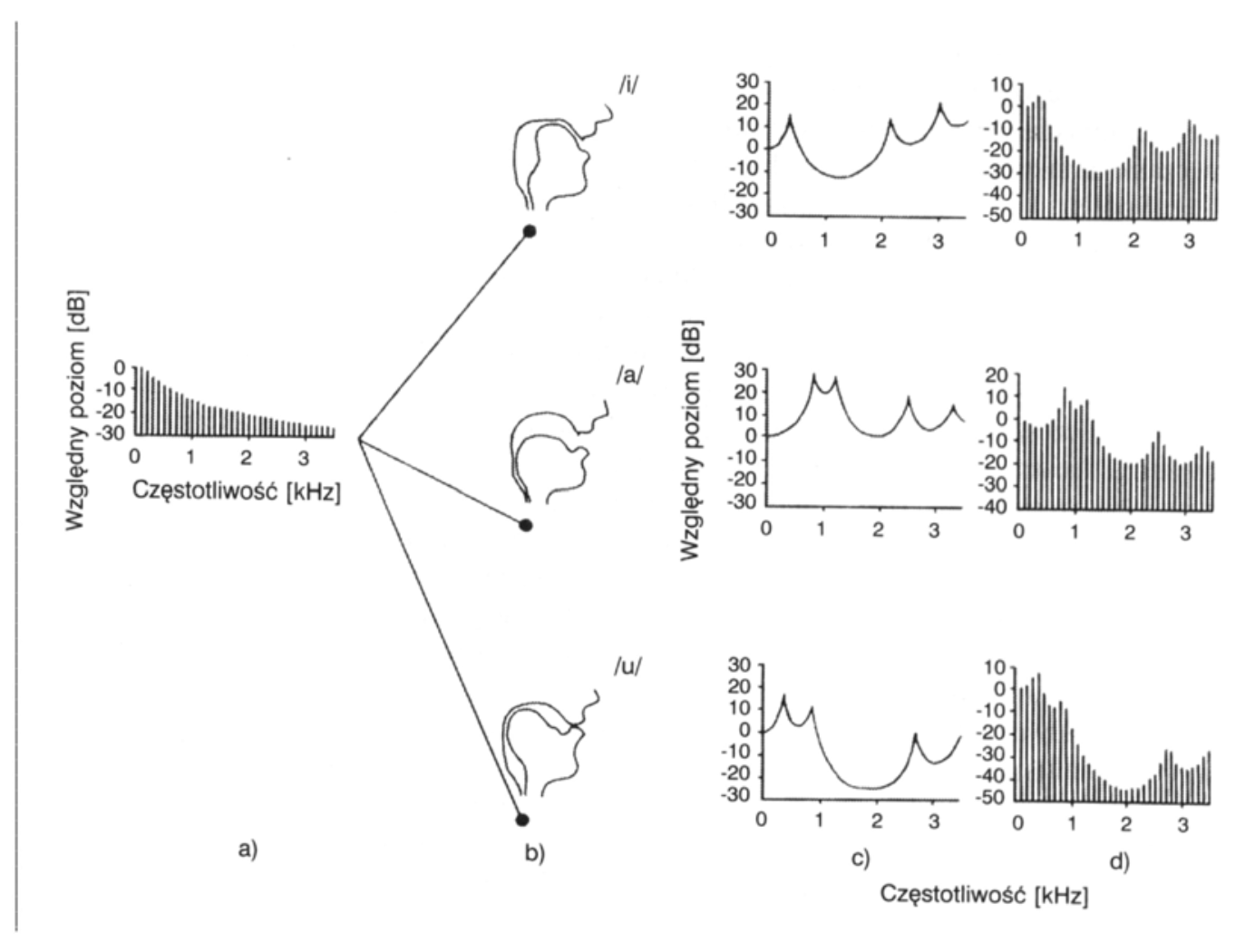
Formanty
Wynikające z rezonansowych właściwości jam ponadkrtaniowych skupienia energii w pewnych zakresach częstotliwości widma nazywa się formantami, a częstotliwość, w której przypada maksimum poziomu w widmie – częstotliwością formantu. Kolejne formanty samogłosek są oznaczane przez F1, F2, F3, F4, a ich częstotliwości przez F1, F2, F3, F4.
Samogłoski są na ogół charakteryzowane poprzez wartości formantów. Wczesne opracowania dotyczące percepcji samogłosek (Delattre i in. 1952; Fry i in. 1962) pokazują, że częstotliwości dwóch lub trzech pierwszych formantów są najważniejsze dla identyfikacji samogłosek. Te tezy zostały potwierdzone przez szereg późniejszych opracowań (Kewley-Port, Atal 1989; Klein i in. 1970; Rackerd, Verbrugge 1985; Terbeek 1977). Na podstawie badań nad polskimi samogłoskami izolowanymi i występującymi w kontekście stwierdzono, że dla ich opisu wystarczające są dwa pierwsze formanty (Jassem 1973; Jassem, Krzyśko, Dyczkowski 1972; Jassem, Szybista, Dyczkowski 1975).
Dwa pierwsze formanty różnią się systematycznie w zależności od położenia masy języka w jamie ustnej. W zakresie formantu pierwszego obserwuje się zależność między jego wysokością a szerokością kanału głosowego – im bardziej otwarta samogłoska, tym F1 jest wyższy. Zatem dla samogłosek polskich F1 rośnie od /i/ poprzez /y/, /e/ do /a/, a następnie opada przez /o/ do /u/. W zakresie formantu drugiego występuje zależność między jego wysokością a układem masy języka - częstotliwość F2 podnosi się w miarę przesuwania masy języka w kierunku wylotu ustnego. Zatem F2 rośnie w kolejności /u/, /o/, /a/, /e/, /y/, /i/. Szereg prac potwierdza istnienie tych akustyczno-artykulacyjnych zależności (Fant 1960, Stevens, House 1955; Lindblom, Sundberg 1971; Jassem 1973; Johnson 2014; Wierzchowska 1965).
Opisane zależności akustyczno-artykulacyjne można zademonstrować, przedstawiając wartości częstotliwości formantów różnych samogłosek polskich w polu dwuwymiarowym, którego oś X przyporządkowuje dźwięki samogłoskowe pod względem pierwszego, a oś Y pod względem drugiego formantu. Uzyskuje się w ten sposób duże podobieństwo do artykulacyjnego trójkąta samogłoskowego, por. rys. 2.
Rys. 2. Odległości akustyczne pomiędzy samogłoskami wymówionymi w izolacji (za Sobierajski, Steffen-Batogowa 2006)
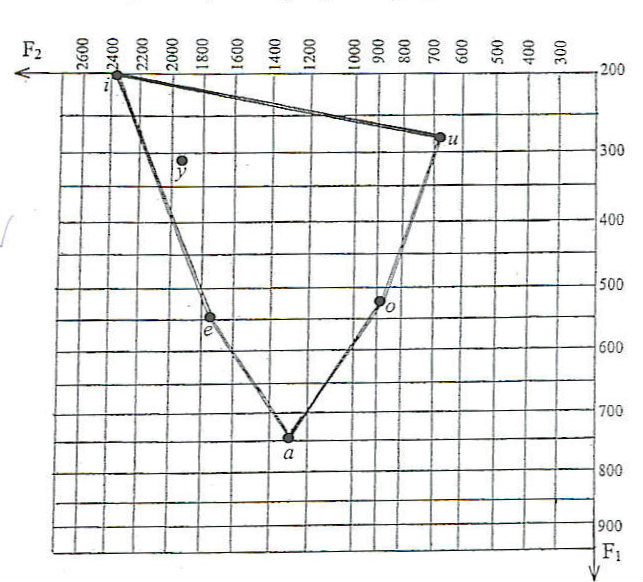
Należy jednak podkreślić, że relacja pomiędzy artykulacją i akustyką jest bardziej skomplikowana niż to przedstawiono wyżej (Stevens, House 1955) i przy ustalaniu artykulacji na podstawie informacji akustycznej wskazana jest daleko idąca ostrożność. Na wartości obu formantów mogą mieć wpływ również takie czynniki jak obniżenie żuchwy, ułożenie krtani czy zaokrąglenie warg. Istnieją również indywidualne różnice między osobami podczas wymawiania samogłosek, związane między innymi z czynnikami anatomicznymi, tempem mowy czy dialektem (Johnson 2014; Johnson i in. 1993; Ladefoged i in. 1972; Lindblom, Sundberg 1971; Wierzchowska 1967).
Innymi słowy, jakakolwiek zmiana w określonej części kanału głosowego ma wpływ do pewnego stopnia na wszystkie formanty (Högberg 1995). Dobrze udokumentowany jest fakt, że zwężeniu ujścia kanału głosowego wskutek zaokrąglenia warg towarzyszy obniżenie wszystkich formantów dźwięku, zwężeniu zaś otworu wskutek spłaszczenia wargowego – podwyższenie częstotliwości formantów drugiego i trzeciego, a także wyższych (Wierzchowska 1967, Lindblom Sundberg 1971, Ladefoged, Disner 2012; Högberg 1995; Harrington 2010). Zaokrąglenie warg i związane z tym obniżenie wartości formantów, ma wpływ zwłaszcza na F3 samogłosek przednich i na F2 samogłosek tylnych (Lindblom, Sundberg 1971). Również ruchy żuchwy mogą powodować przesunięcia formantu pierwszego o kilkaset Hz – wartości F1 wzrastają wraz z większym otwarciem szczęki (Lindblom, Sundberg 1971). Obniżenie krtani o ok. 10 mm obniża wartości wszystkich formantów, a zwłaszcza drugiego i czwartego (Lindblom, Sundberg 1971).